
Scrabble's letter distributions: Art or science?
Thanks to Lance's python wizardry, we now have lexicon-based letter distribution counts! (See his comment to the previous post.) Interestingly, comparing the lexicon and corpus-based counts side by side with the Scrabble counts, some odd discrepancies appear.
Here's some bar charts summarizing the results. The leftmost (blue) bar represents Lance's lexicon letter counts. The center (red) bar represents the corpus letter counts. And the rightmost (yellow) bar represents the Scrabble tile distribution (as if it's out of 100, though it ought to be 98, because of the two blank tiles).
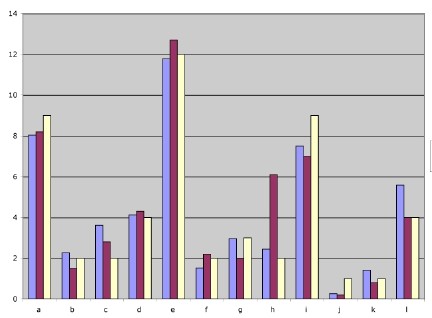 A-L
A-L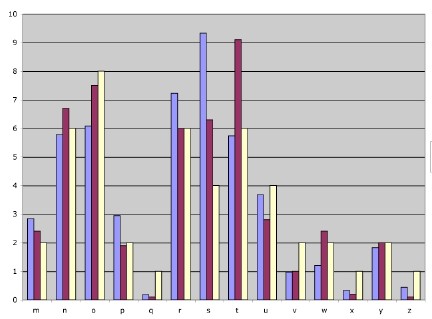 M-Z
M-ZThere are a few differences between the corpus and lexicon counts. As Lance notes, the letter 'h' occurs in the corpus way more frequently than it does in the lexicon (the, he, her, their, those, them,...). The letter 't' as well, is more frequent in the corpus than the lexicon. Weirdly, the letter 's' is underrepresented in the corpus compared to the lexicon; I wonder if the headword list Lance chose included plurals of all the nouns?
What's interesting is that the Scrabble tile distribution matches lexicon frequency in some cases of discrepancy, corpus frequency in other cases, and neither in a couple of cases. This seems like a possibly odd result, given that the Scrabble letter distribution was supposed to have originally been based on a corpus count consisting of NYT front pages. Either the front pages on the days in question had some exceptional trends in letter usage (see below) or the creator of Scrabble, Alfred Mosher Butts, adjusted some frequencies based on his intuitions about what would make the game go better.
Of course, for letters whose frequency is less than 1%, Scrabble has a higher distribution because you can't have a letter with less than one tile. So 'q', for instance, is overrepresented in Scrabble, of necessity.
Other variations, though, seem to be more a matter of intuitive game-play facilitation. 'S', for instance, is less frequent in Scrabble than in either the lexicon or corpus -- obviously 's' makes high-scoring hooks easy, increasing its value as a letter, and Alfred foresaw this and deliberately made them scarcer. On the other hand, there's twice as many 'v's as there ought to be, as anyone who's tried to find a good way to use one knows (there are no two letter words with 'v' in them -- hard to hook). On the mitigating side, there's fewer 'c's than there ought to be, at least comparing to the lexicon distribution; ought to be 3, but there's only 2 'c' tiles. Since there's also no legal two letter words with 'c', that's kind of nice. I find it hard to imagine that Alfred was thinking about the availability of two-letter words, though maybe he was. Elsewhere, there's too many 'i's, compared to the lexicon count, and too many 'o's, but two few 'l's. In the latter two cases the corpus and Scrabble counts match pretty well, but he must just have been being perverse about the 'i's, because there the extra-high Scrabble count matches neither the lexicon nor the corpus count. (It does often feel like there are too many 'i's, IMHO.)
Anyway, thanks to Lance for pulling this data out! I think it's interesting how the two counts are actually not all that different. In the phonological version of this, of course, the edh segment would be the one with the way high count compared to the lexicon (rather than 'h' or 't' -- though maybe /h/ would also be high because of the pronouns). I wonder if any others would also exhibit significant mismatch?
Update: Check out this series of posts on the same topic at Nikolasco:
Scrabble Distributions
Best Fit Scrabble Letter Distribution
Super Scrabble
I was especially interested to see the results of his 'Best Fit' computations, and the discussion of Super Scrabble (which I have found to be actually quite a lot of fun—a more freewheeling game, especially with four players.)
Also, check out this post from Patrick Hall on Blogamundo about helping linguists execute their programming inclinations. Thanks for the thought, Patrick! I'll be watching for the updates.
posted by hh @ 9:52 PM
![]()
4 Comments:
I just made a somewhat similar post, but comparing tile and lexical frequencies for British and American dictionaries.
I found this blog post by doing a google search for: scrabble frequency. This post was fifth in the results.
Fascinating blog, I'm adding you to my weekly check. :-)
My friends and I definitely think there are too many I's. We very often have more than one of them. We hate them.
初音ミク網頁設計会社設立グループウェア探偵浮気調査コンタクトレンズ腰痛名刺作成留学矯正歯科インプラント電報ショッピング枠 現金化クレジットカード 現金化ジュエリーおまとめローン格安航空券電話占いワンクリック詐欺カラーコンタクトクレジットカード 現金化多重債務国内格安航空券債務整理債務整理薬剤師 求人葬儀 千葉フランチャイズフランチャイズ幼児教室個別指導塾経営雑誌経済雑誌似顔絵ウェルカムボードCrazyTalkCloneDVDCloneCDクレージートークフロアコーティング 川崎フロアコーティング会社設立埼玉 不動産フロント 仕事治験お見合いインプラントキャッシング東京 ホームページ制作別れさせ屋システム開発サーバー管理育毛剤育毛剤不動産渋谷区 賃貸
Post a Comment
<< Home